Avant d’y référencer votre site, savez-vous ce que l’outil de recherche que vous utilisez au quotidien a “dans le ventre” ? Pas si simple, car si des moteurs comme Google, Yahoo! ou MSN Search semblent simplissimes à l’utilisation, sous leur capot sommeille souvent un tigre redoutable. Nous vous proposons dans ce chapitre une analyse globale du fonctionnement des moteurs et des processus qui sont mis en oeuvre pour traiter les documents, stocker les informations les concernant et restituer des résultats aux requêtes des utilisateurs. En effet, bien maîtriser le fonctionnement d’un moteur permet de bien mieux appréhender le référencement et l’optimisation de son site.
Un moteur de recherche est donc un ensemble de logiciels parcourant le Web puis indexant automatiquement les pages visitées. Trois étapes sont indispensables à son fonctionnement :
- La collecte d’information (ou crawl) grâce à des robots (ou spiders ou crawlers).
- L’indexation des données collectées et la constitution d’une base de données de documents nommée “index”.
- Le traitement des requêtes, avec en particulier un système d’interrogation de l’index et de classement des résultats en fonction de critères de pertinence suite à la saisie de mots clés par l’utilisateur de l’outil.
Deux principaux types de contenus sont actuellement affichés par les moteurs dans leurs pages de résultats, comme nous l’avons vu dans les pages précédentes : - les liens “organiques” ou “naturels”, obtenus grâce au “crawl” du Web. - les liens sponsorisés.
Nous allons nous concentrer ici en priorité sur les techniques utilisées par les moteurs pour indexer et retrouver des liens “naturels” et nous n’aborderons pas le traitement spécifique des liens sponsorisés (liens commerciaux, traités au chapitre 7 de cet ouvrage).
Technologies utilisées par les principaux portails de recherche
En dehors des trois leaders du marché (Google, Yahoo et MSN), de nombreux moteurs n’utilisent pas leurs propres technologies de recherche mais ils sous-traitent cette partie auprès de grands moteurs. En fait il n’existe que peu de “fournisseurs de technologie” sur le marché : Google, Yahoo!, MSN, Teoma, Wisenut et Gigablast aux Etats-Unis, comme sur le plan mondial, sont les principaux. Exalead, Mirago et Voila sont les acteurs majeurs en France, à côté d’autres moins connus comme Antidot, Deepindex, Seekport, Misterbot ou Dir.com (mais il en existe d’autres). Voici un tableau récapitulatif des technologies utilisées par les différents portails de recherche en 2006 :

Pourquoi faut-il éviter les pages satellites ?
Il y a fort à parier que la prochaine “charette” des moteurs portera sur le contenu caché à l’intérieur des pages web que l’on voit de plus en plus apparaître sur le réseau. Les trois techniques d’optimisation à éviter dorénavant semblent donc être :
- A court terme, les pages satellites.
- A moyen terme, le texte et les liens cachés (fonctions “visibility:hidden” ou “display:none”, utilisation de balises “noscript” n’ayant aucun rapport avec la balise “script” qu’elles accompagnent, voire sans balise “script” du tout...) dans les pages.
- A long terme (mais cette notion reste toute relative sur le Web...), toute “manipulation” sur des noms de domaine différents pointant par exemple vers la même page d’accueil d’un site. Si Google a acquis un statut de “registrar” (http://actu.abondance.com/2005-05/google-registrar.php), ce n’est pas obligatoirement pour vendre des noms de domaines, mais plutôt pour avoir un accès plus complet aux données les concernant...
La conclusion nous semble donc évidente : exit les pages satellites pour les mois qui viennent. Le seul vrai “bon” référencement est bien celui qui est basé sur l’optimisation “à sa source” du site web lui-même, sans information cachée dans les pages et sans page satellite. Ceux qui seront blacklistés ou pénalisés dans un proche avenir pour avoir abusé des pages satellites ne pourront pas dire qu’ils n’ont pas été prévenus...
Il ne reste plus alors qu’aux webmasters à envisager un référencement basé sur l’optimisation “à sa source” du site web lui-même, sans information cachée dans les pages et sans page satellite. Ce qui donne d’ailleurs d’excellents résultats, comme vous allez pouvoir vous en rendre compte en lisant cet ouvrage. Ou à inventer de nouvelles possibilités de contourner les algorithmes des moteurs. Et le jeu des gendarmes et des voleurs continuera alors... Jusqu’à quand ?
Ces arguments nous semblent suffisants pour bien réfléchir avant de mettre en place une stratégie basée sur les pages satellites. La situation, à notre avis, est similaire à celle des balises “meta”, il y a quelques années de cela :
1. Les balises meta (“description” et “keywords”, voir chapitre 3) étaient une solution idéale pour les moteurs de recherche puisqu’elles permettaient de fournir à ces derniers des informations sur le contenu des pages de façon transparente. Les pages satellites permettent également de pallier des problèmes techniques pouvant bloquer un référencement (Flash, sites trop graphiques ou dynamiques, etc.).
2. Certains webmasters sont allés trop loin et ont réellement fait “n’importe quoi” avec les balises meta, les truffant notamment de mots clés n’ayant aucun rapport avec le contenu du site ou indiquant de nombreuses occurrences d’un même terme, etc. Les pages satellites connaissent actuellement les mêmes abus, certains référenceurs y ajoutant par exemple de façon cachée des liens vers leur propre site, voire, encore pire, vers les sites d’autres clients histoire d’en améliorer la popularité...
3. Que s’est-il passé, à l’époque, pour les balises meta ? Les moteurs en ont eu assez des excès de certains webmasters et ont, dans leur immense majorité, décidé de ne plus prendre en compte ces champs dans leur algorithme de pertinence. Les webmasters qui, eux, les géraient de façon “propre” en ont fait les frais... Nous vous laissons le choix de la réflexion quant à la façon dont va se passer l’étape “3” pour les pages satellites... Les moteurs sont clairs aujourd’hui sur ce point : les pages satellites sont du spam et doivent être abandonnées...
Il est très important de bien comprendre que la page satellite ne doit pas obligatoirement être considérée comme un “délit” en soi. Il fut une époque où cela marchait très bien et où la communication à ce sujet par les moteurs de recherche était plus que floue... Mais la multiplication des abus a amené les moteurs à supprimer ce type de pages de leurs index. Ceux qui auront basé toute leur stratégie de référencement sur ces “rustines” - et auront certainement payé très cher pour cela - en seront alors pour leurs frais... Cela deviendra aussi inutile que de baser tout son référencement sur l’usage des balises meta “keywords”, globalement inefficaces aujourd’hui... A bon entendeur salut :-)
Mais ne nous y trompons pas : la majorité des sociétés de référencement en France n’utilise plus à la mi-2006 les pages satellites comme système de référencement / positionnement et basent plutôt leur stratégie sur le conseil et l’optimisation des pages existantes du site voire la création de véritables pages de contenu optimisées. Là est la véritable voie de réflexion pour l’avenir... En revanche, les entreprises orientées “pages satellites” devront clairement et très rapidement réfléchir à leur avenir et à leurs méthodologies avant qu’il ne soit trop tard...
Puissiez-vous en être persuadé à la lecture de ce chapitre : la page satellite est une technologie qui peut aujourd’hui être considérée comme obsolète, voire dangereuse. Elle DOIT être abandonnée ! Mais pour cela, il faut absolument que tous les acteurs de la chaîne de la création de site web soient clairement persuadés que chacun doit et peut avancer dans le même sens :
- Le propriétaire d’un site web doit être conscient que, pour obtenir une bonne visibilité sur les moteurs de recherche, certaines concessions, notamment techniques, doivent être faites (moins de Flash, de JavaScript, plus de contenu textuel, etc.).
- Le créateur du site web (web agency) doit être formé aux techniques d’optimisation de site et conseiller, en partenariat avec le référenceur, de façon honnête, le client sur ce qui est possible et ce qui ne l’est pas.
- Le référenceur doit garantir la non utilisation de pages satellites ou d’autres procédés aujourd’hui clairement refusés et interdits par les moteurs de recherche. Il est possible d’obtenir une excellente visibilité sur un moteur de recherche en mettant en place une optimisation “propre”, loyale, honnête et pérenne, et sans artifice ni “rustine” à durée de vie limitée... Le tout est surtout de partir d’une base la plus “saine” possible, c’est-à-dire d’un site web préparé dès le départ pour le référencement...
La Balise <title>
La balise “Titre” est un champ essentiel dans le cadre d’une bonne optimisation, puisqu’il est l’un des critères les plus importants (pour ne pas dire le plus important) pour la majeure partie des moteurs actuels et notamment Google.
Le titre d’une page est affiché en haut de la fenêtre de votre navigateur Internet, lorsque vous consultez un site. Exemple ici (sous Windows XP) pour le site Abondance.com :

(...)
Libellé du titre
En ce qui concerne le libellé du titre, choisissez une expression qui affiche le plus possible de mots clés déterminants et caractéristiques de votre activité.
Evitez les expressions banales, comme “Bienvenue”, “Homepage” (pire : “Bienvenue sur ma Homepage” ou “Bienvenue sur notre site web”), “Welcome”, “Accueil”, “Page d’accueil”, etc. Tous ces titres sont à proscrire car loins d’être assez descriptifs. Le titre d’une page d’accueil, par exemple, doit contenir au moins le nom de votre entreprise / entité / organisme / association (rayez les mentions inutiles...) et décrire en quelques mots son activité.
De même, n’oubliez pas de donner un titre à vos pages (le nombre de pages web n’ayant pas de titre - souvent, la mention “Untitled” apparaît dans les résultats des moteurs - sur la toile est considérable !!). La requête “intitle:untitled”, qui donne sur Google le nombre de pages web ayant le mot “untitled” dans leur titre, donnait à la mi-2006 plus de 100 millions de résultats...
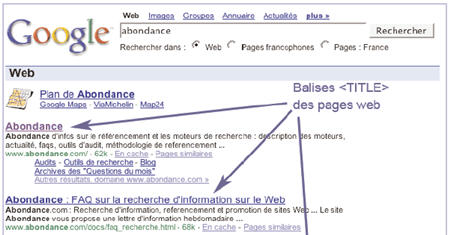 Le contenu de la balise <TITLE> est repris par les moteurs de recherche dans leurs pages de résultats pour désigner les pages en question.
Le contenu de la balise <TITLE> est repris par les moteurs de recherche dans leurs pages de résultats pour désigner les pages en question.
On s’accorde à penser le plus souvent qu’un titre bien optimisé propose au plus 10 mots descriptifs dans son libellé. Ne proposez donc pas de titres trop longs (une fourchette entre 5 et 10 termes semble un bon compromis), certains moteurs semblent ne les apprécier que modérement. Dans ces dix mots, vous ne compterez pas les “stop words” ou “mots clés vides” comme “le”, “la”, “à”, “au”, “vos”, etc. Retenez donc que les titres de vos pages doivent contenir de 5 à 10 mots descriptifs...
En revanche, rien ne prouve actuellement que l’emplacement d’un mot dans le titre (au début, au milieu ou à la fin) confère à la page qui le contient un avantage en termes de positionnement. Si les mots importants pour décrire le contenu de la page sont dans le titre, c’est déjà une excellente chose...
Attention à ne pas répéter trop souvent certains mots clés, cela pourrait être pris pour du spam (fraude) par certains moteurs. Si un mot est répété, essayez d’en espacer le plus possible les occurrences. Par exemple, positionnez un mot important deux fois dans le titre en le plaçant en 1ère et 7ème position. Ou en 2ème et 8ème, etc.
Si un mot précis caractérise de façon quasi-parfaite votre activité (il peut s’agir de votre nom ou d’un terme professionnel ou autre), essayez de le “caser” deux fois dans le titre de vos pages. Si possible, tentez de faire en sorte que chaque mot du titre soit unique (non répété) sauf un terme important qui soit proposé en double.
N’oubliez pas les codes HTML pour les lettres accentuées (é pour la lettre é, par exemple), car il s’agit là d’un texte à part entière. Sachez qu’il existe d’autres “écoles” pour le codage - ou non - des lettres accentuées. Certains référenceurs ne les codent pas (“é” reste “é” et pas “é”), d’autres les proposent non accentuées, etc. Il ne semble pas exister de “recette miracle” dans ce domaine... A vous de voir la solution qui vous convient le mieux. Sachez cependant que les lettres accentuées non codées en HTML s’affichent parfois mal sur certains navigateurs et que les lettres non accentuées (alors qu’elles devraient l’être) peuvent choquer certains internautes qui pourraient croire à des fautes de frappe ou d’orthographe... Eh oui, n’oubliez jamais que le titre est lu par les internautes !
PageRank et indice de popularité
Ce n’est un secret pour personne, tous les moteurs de recherche majeurs actuels, de Google à MSN en passant par Yahoo! et Exalead, utilisent l’indice de popularité (ou “link popularity”, ou “link analysis” en anglais) dans leurs critères de pertinence. On peut même dire que ce paramètre est aujourd’hui devenu une partie importante des algorithmes de pertinence et que l’indice de popularité (IP) figure parmi les cinq critères majeurs sur tous les moteurs, avec le titre des pages, le texte visible, l’url et la réputation.
__
Comment l’indice de popularité est-il calculé ?__
Au départ, il y a quelques années de cela, cet indice de popularité n’était calculé que selon un mode quantitatif : plus une page avait, dans l’index du moteur, de liens qui pointaient vers elle, plus son indice de popularité était élevé. Il n’en est rien aujourd’hui et tous les moteurs de recherche ont mis en place des modes de calcul bien plus élaborés pour quantifier ce critère, en tenant notamment compte de la “qualité” des liens trouvés vers la page “cible”. Il n’est donc pas réellement nécessaire d’avoir énormément de liens pointant vers vous pour être bien classé sur Google ou Yahoo!, mais il vaut mieux, et de plus en plus, avoir des liens “à forte valeur ajoutée”. Pas obligatoirement plus que vos concurrents, mais de meilleure “qualité”, donc émanant de pages elles-même populaires.
 Google utilise fortement l’indice de popularité dans son algorithme baptisé PageRank (du nom de son co-créateur Larry Page). Il est affiché dans la barre d’outils de Google sous la forme d’une “note” allant de 0 à 10.
Google utilise fortement l’indice de popularité dans son algorithme baptisé PageRank (du nom de son co-créateur Larry Page). Il est affiché dans la barre d’outils de Google sous la forme d’une “note” allant de 0 à 10.
Aujourd’hui, donc, les moteurs de recherche utilisent plusieurs familles de données et de critères pour calculer ce paramètre (rappelons que le calcul est effectué sur la base des pages présentes dans l’index du moteur et seulement celles-ci, il ne sert à rien d’avoir des liens “forts” vers son site, encore faut-il que les pages qui les contiennent soient bien dans l’index du moteur en question pour être prises en compte). Voici quelques données qui devraient vous être utile pour améliorer votre situation à ce niveau :
- Les aspects quantitatif et qualitatif sont le plus souvent pris en compte à deux niveaux. Le moteur calcule non seulement l’IP d’une page, mais également celui des pages pointant vers lui. Donc, un lien depuis une page à forte popularité vaudra plus “cher”, sera plus “important” qu’un lien émanant d’une page perso lambda. Il peut suffire d’avoir peu de liens mais provenant de pages très populaires, plutôt qu’une multitude de liens émanant de pages peu connues et isolées. Le quantitatif a vécu, place au qualititatif... Ceci dit, si vous disposez d’une multitude de liens émanant de pages très populaires, c’est encore mieux ;-)
- Le nombre de liens présents dans les pages pointant vers vous est également de plus en plus important (voir la formule de calcul de Google ci-après). Plus la page qui pointe vers vous proposera de liens divers et variés, plus son importance diminuera, plus elle sera “diluée” parmi tous les liens proposés. Ceci pour défavoriser les longues pages de liens, de type FFA (voir plus loin), qui sont rarement lues et n’ont finalement que peu d’intérêt, autre que celui de faire croire qu’elles vont augmenter votre IP, ce qui est faux en grande partie.
- Le fait que les liens vers une page soient internes ou externes peut être important. Certains moteurs peuvent compter les liens internes de votre site dans leurs calculs, soit les exclure (rarement), soit leur donner un poids plus faible (le plus souvent) pour prendre plus en considération les liens provenant d’autres sites que le vôtre, ce qui est assez logique.
- L’indice de popularité est calculé par rapport à une page précisemment, pas pour un site de façon globale. La page d’accueil de votre site aura donc, le plus souvent, le plus important indice de popularité parmi toutes vos pages , car il y a fort à parier - sauf exception - que la plupart des liens du Web renvoient vers elle. Attention, notamment à la façon dont vos pages sont adressées. Exemple : la page d’accueil du site Abondance est accessible au travers des adresses : abondance.com, www.abondance.com, www.abondance.net, www.abondance.fr, www.abondance.com/index.html, etc. Sur certains moteurs, chaque url sera considérée comme un site différent. Sur d’autres, peu importe l’adresse, toutes les formulations seront identiques.
- Seuls les liens pointant vers vous (appelés “liens entrants” ou “backlinks”) sont pris en compte. Les liens émanant de vos pages pour aller vers d’autres sites (“liens sortants”) ne sont pas pris en considération dans le calcul de l’indice de popularité de cette page actuellement.
De la difficulté d'indexer les sites dynamiques
Le fait que les urls dynamiques aient un format spécifique ne nous explique pas pourquoi elles sont refusées par les moteurs de recherche. Il y a en fait plusieurs explications à cela :
- Le nombre de pages créées “à la volée” par un site dynamique peut être quasi infini. En effet, prenez un catalogue du type de ceux d’Amazon ou de la Redoute, multipliez le nombre d’articles par le nombre d’options possibles (délai d’envoi, couleur, taille pour des vêtements, autres possibilités diverses et variées) et vous obtenez rapidement, pour un seul site, plusieurs centaines de milliers, voire millions de pages web potentielles présentant chaque produit de façon unique. Difficile, pour un moteur, de les indexer toutes ou, en cas contraire, de savoir où s’arrêter.
- Un site web dynamique a la possibilité de créer, en quelques secondes, des milliers de pages “à la volée”. Il s’agit également là d’un système à haut risque pour ce qui concerne le spam contre les moteurs. Dans ce cas, ces derniers “se méfient” et, parfois, optent pour l’option la moins risquée... Ils préfèrent ne prendre en compte aucune page plutôt que de courir le risque de devenir un “réservoir à spam” au travers de techniques de création incessante de pages... un peu trop optimisées...
- Une même page, proposant le même contenu, peut être accessible à l’aide de deux urls différentes (ce problème est notamment crucial en ce qui concerne les identifiants de session, voir plus loin). Cela risque d’être problématique pour un moteur, qui devra alors mettre en place des procédures de “dédoublonnage” qui peuvent s’avérer complexes...
- La longueur excessive de certaines urls, passant de nombreux paramètres, peut également poser des problèmes aux moteurs. D’autre part, certains caractères apparaissant dans ces adresses (#, {, [, |, @, etc.) peuvent parfois être bloquants, tout comme les lettres accentuées, peu fréquentes dans les urls statiques, qui peuvent causer des soucis de codage.
Certains problèmes posés par les sites web dynamiques sont appelés “spider traps” : il s’agit de pages mal reconnues par les “spiders” des moteurs, qui s’y perdent parfois dans des boucles infinies et indexent alors des milliers de documents différents représentatifs de quelques pages web uniquement.
Retour sur investissement : différents types de calcul
La notion de “profitabilité” peut être très vaste. Il ne s’agit pas uniquement d’un accroissement du chiffre d’affaires dû à un achat en ligne, qui sera certainement le but d’un site de commerce électronique. Les objectifs peuvent être très variés. En voici quelques-uns :
- Vente en ligne : l’éditeur du site veut que l’internaute achète chez lui ou prépare un achat pour une prochaine visite. Dans ce cas, le critère retenu est donc le chiffre d’affaires généré. Le ROI sera alors égal à :
ROI = Chiffre d’affaires généré par des visiteurs issus des outils de recherche / Coût du référencement
Ce calcul peut être effectué en fonction du chiffre d’affaires, de la marge brute, de la marge nette, etc., en fonction des besoins de l’éditeur du site. Selon le paramétrage de son système de “tracking”, un client qui achète un mois après être venu sur le site pour la première fois sera pris en compte ou non.
- Notoriété active : l’éditeur veut que l’internaute vienne sur son site pour y passer du temps. L’objectif se situe au niveau de la marque, d’une bonne gestion de la notoriété de l’entreprise et de sa visibilité. Le ROI sera, dans ce cas, calculé en fonction du temps passé par l’internaute sur le site, le nombre de pages vues par visite,etc. Exemple : Renault sort une nouvelle voiture et il veut que 10 000 internautes/mois se connecte sur la page qui la présente.
Le calcul de son ROI se fait sur la base suivante :
ROI = Durée des visites des internautes issus des outils de recherche / Coût du référencement
ou :
ROI = Nombre de visites d’internautes issus des outils de recherche / Coût du référencement
- Notoriété passive : l’éditeur veut que l’internaute voie sa marque sans pour autant vouloir amener l’internaute sur son site.
Son ROI sera calculé en fonction du nombre d’affichage/jour-semaine-mois. Cela peut, par exemple, correspondre à une campagne de liens sponsorisés. Exemple : Un constructeur automobile veut que sa marque soit affichée dans les 5 premiers résultats du mot “pick-up” sans être leader en pôle position car il n’a pas un modèle récent dans cette catégorie de véhicule.
Son ROI sera calculé sur :
ROI = Nombre de fois ou le lien est affiché dans les pages de résultats / Coût du référencement ou de la campgane de liens sponsorisés
- Recrutement / actions opt-in : L’éditeur veut que l’internaute réalise un “acte” sur son site. Un “acte” peut être le remplissage d’un formulaire, l’abonnement à une newsletter, l’incription en tant que membre, une demande d’information sur un produit/ service...
Dans ce cas, le ROI sera calculé sur la base suivante :
ROI = Nombre d’actes effectués par des visiteurs issus des outils de recherche / Coût du référencement
Il peut exister bien d’autres possibilités de calcul de ce ROI, en fonction du type de site et des informations / ressources / produits / services qu’il propose.
Ce type de calcul peut également être effectué pour de nombreuses actions de promotion :
- Bannières de publicité.
- Référencement.
- Positionnement publicitaire (liens sponsorisés de type adCenter, Google, Overture).
- Echange de lien : quel site pointant vers vous génère le trafic le plus qualifié ?
- Insertion de liens dans une newsletter.
- Sponsoring de zones à l’intérieur d’un site (exemple : un fleuriste pour la Saint Valentin).
- Etc.
www.journaldunet.com
